今天要為cifar10訓練一個模型,它相較mnist來說,難度提高了不少,我們先從簡單的模型架構開始,看看我們有什麼能改善的。
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train / 255
x_test = x_test / 255
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
from tensorflow.keras.models import Sequential
model = Sequential()
from tensorflow.keras.layers import Conv2D, Dense, Dropout, Flatten, MaxPool2D
model.add(
Conv2D(
filters = 64,
input_shape = (32, 32, 3),
kernel_size = (3, 3),
strides = (1, 1),
padding = 'same',
activation = 'relu'
)
)
model.add(
MaxPool2D(
pool_size = (2, 2)
)
)
model.add(
Conv2D(
filters = 64,
kernel_size = (3, 3),
strides = (1, 1),
padding = 'same',
activation = 'relu'
)
)
model.add(
MaxPool2D(
pool_size = (2, 2)
)
)
model.add(
Conv2D(
filters = 64,
kernel_size = (3, 3),
strides = (1, 1),
padding = 'same',
activation = 'relu'
)
)
model.add(
MaxPool2D(
pool_size = (2, 2)
)
)
model.add(
Flatten()
)
model.add(
Dropout(
rate = 0.2
)
)
model.add(
Dense(
units = 10,
activation = 'softmax'
)
)
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
model.summary()
from tensorflow.keras.callbacks import ModelCheckpoint, CSVLogger, TerminateOnNaN, EarlyStopping
mcp = ModelCheckpoint(filepath='cifar10-{epoch:02d}.h5', monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=False, mode='auto', save_freq='epoch')
log = CSVLogger(filename='cifar10.csv', separator=',', append=False)
ton = TerminateOnNaN()
esl = EarlyStopping(monitor='val_loss', patience=7, mode='auto', restore_best_weights=True)
esa = EarlyStopping(monitor='val_accuracy', patience=7, mode='auto', restore_best_weights=True)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
width_shift_range = 0.1,
height_shift_range = 0.1,
shear_range = 0.1,
rotation_range = 20,
horizontal_flip = True
)
from sklearn.model_selection import train_test_split
import time
x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.1, random_state=int(time.time()))
batch_size = 50
hist = model.fit(
x = datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch = x_train.shape[0] // batch_size,
epochs = 50,
validation_data = (x_valid, y_valid),
callbacks = [mcp, log, ton, esl, esa],
verbose = 2
)
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dropout (Dropout) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 10) 10250
=================================================================
Total params: 85,898
Trainable params: 85,898
Non-trainable params: 0
_________________________________________________________________
Test loss = 0.6636186135292054
Test accuracy = 0.7777
77.77%的正確率,看來我們還有很多進步的空間,比起mnist一開始的97%少了很多,這還是我們已經應用了前面所提到的技巧後的成績,我們畫些錯誤的圖出來看一下。
y_predict = model.predict(x_test)
import numpy as np
y_predict = np.argmax(y_predict, axis=1)
y_test = np.argmax(y_test, axis=1)
wrong = np.not_equal(y_predict, y_test)
label = np.arange(*y_test.shape)[wrong]
text = ['飛機', '汽車', '鳥' ,'貓', '鹿', '狗', '青蛙', '馬', '船', '卡車']
import matplotlib.pyplot as plt
from random import choice
plt.figure(figsize=(16,10),facecolor='w')
for i in range(5):
for j in range(8):
index = choice(label)
plt.subplot(5, 8, i*8+j+1)
plt.title("label: {}, predict: {}".format(text[y_test[index]], text[y_predict[index]]), fontproperties="Microsoft YaHei")
plt.imshow(x_test[index])
plt.axis('off')
plt.show()

大多都是把一種動物辨識成另一種動物,或是一種交通工具辨識成另一種交通工具,混淆兩者的情況沒有太多,模型還是有學到一些東西的,畫個混淆矩陣來看,因為要把標籤換成中文,所以改了一下程式。
import pandas as pd
import numpy as np
y_test = np.array(list(map(lambda x: text[x], y_test)))
y_predict = np.array(list(map(lambda x: text[x], y_predict)))
df = pd.DataFrame({'y_Actual': y_test, 'y_Predicted': y_predict})
pd.crosstab(df['y_Actual'], df['y_Predicted'], rownames=['Actual'], colnames=['Predicted'])
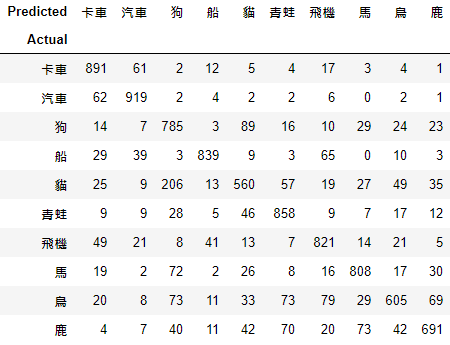
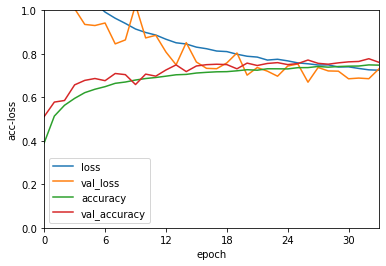
貓好像經常被誤認為狗,發生了206次,不過也不能怪模型了,這圖解析度也不高,有些圖片用人眼看也需要一些時間才能反應出來,這裡畫個訓練時的loss和accuracy給大家看吧,程式有所更改,因為我們將epoch調高了,也有可能發生EarlyStopping的情況,所以不能把數字寫死了,在本次訓練中,模型在第34次epoch停止,模型被回退到第27次時的狀態了,比起mnist的圖看起來,有種掙扎的感覺。
history = hist.history
epoch = len(history['loss'])
x = np.arange(epoch)
plt.figure(facecolor='w')
plt.plot(x, history['loss'], label='loss')
plt.plot(x, history['val_loss'], label='val_loss')
plt.plot(x, history['accuracy'], label='accuracy')
plt.plot(x, history['val_accuracy'], label='val_accuracy')
plt.xlim(0, epoch-1)
plt.xticks([i for i in range(0,epoch,epoch//5)],[str(i) for i in range(0,epoch,epoch//5)])
plt.xlabel('epoch')
plt.ylim(0,1)
plt.ylabel('acc-loss')
plt.legend()
plt.show()